



对于搞机党或者开发人员来说,root 一定是一个不陌生的名词。在 当我们谈论解锁 BootLoader 时,我们在谈论什么? 一文中我们了解到,解锁 Bootloader 实际上能做到的是让手机可以运行第三方的操作系统,而通常来说,我们给手机解锁 Bootloader 就是为了获取 Root 权限。那么,何为 root?,解锁 Bootloader 和 root 到底有什么联系和区别?
In Unix-like computer OSes (such as Linux), root is the conventional name of the user who has all rights or permissions (to all files and programs) in all modes (single- or multi-user).
维基百科说,在类 Unix 系统中,root 是在所有模式(单用户或多用户)下对所有文件和程序拥有所有权利或许可的用户的名称。
现代操作系统(本文主要讨论 Android 系统,下同)一般都是多用户的,那个名为 root 的用户所拥有的权限就是 root 权限;而 root 权限中有三个「所有」,可以简单这么理解:root 意味着最高权限;不过,这么描述不够具象,接下来就带大家了解一下 root 的方方面面。
root 的来源
在类 Unix 系统中, 一切皆文件。而这些文件通常以一个分层的树形结构在文件系统中呈现,每一个文件都有一个父目录,而那个最顶层的父目录被称之为根目录 (root directory);root 用户之所以被称之为 root,大抵是因为它是唯一能修改 root directory 的用户。
因为 root 用户拥有最高权限,因此它也通常被称之为超级用户 (superuser);在类 Unix 系统中,每一个用户都有一个 ID,root 用户的 ID 是 0,从传统意义上讲,uid 为 0 就是 root 用户,也就拥有最高权限。
最高权限具体指的哪些?
我们一直在说,「最高权限」,那么最高权限到底是哪些呢?
直白点来说,手机是由多个零部件组成的,比如说,CPU、内存、闪存、各种硬件设备(如相机,屏幕、传感器等),所谓最高权限,就是对所有这些设备的控制权。
对于 CPU 来说,现在的 CPU 芯片一般都有不同的特权等级,这些不同的等级可以执行不同的指令。就拿 AArch64 构架来说,CPU 有四个特权等级,EL0 ~ EL3:
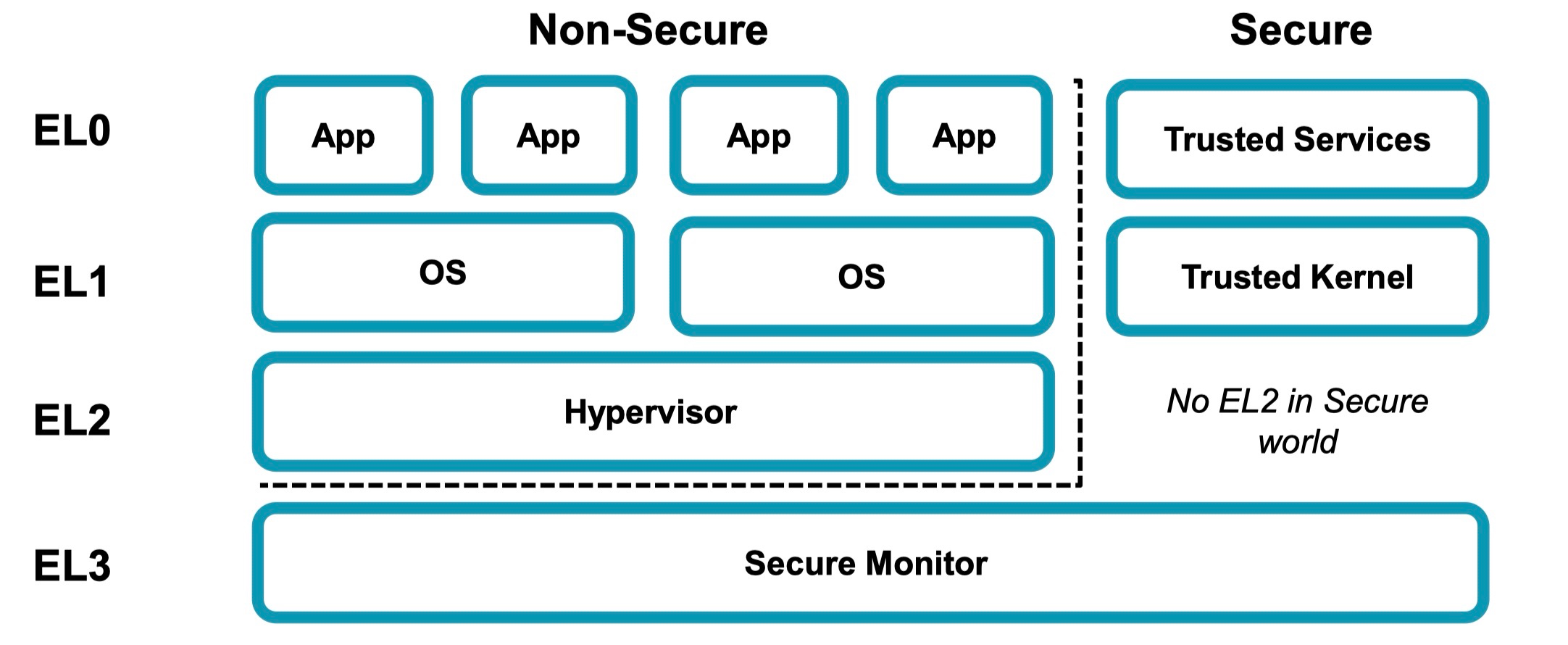
在不考虑 Secure World 的情况下(感兴趣的可以 google TrustZone),EL0 就是通常所谓的用户空间,应用程序一般运行在 EL0 级别,操作系统(Linux 内核及驱动)运行在 EL1,EL2 上运行的则是虚拟化相关程序,EL3 则运行管理 Secure World 和 Normal Wrold 的 Secure Monitor。
从严格意义上来说,既然 root 权限意味着最高权限,这应该代表着它可以在 EL0 ~ EL3 中的任意 level 上执行任意的 CPU 指令。然而,当前的各种 root 实现并非如此,它们一般能在 EL0 上执行任意指令,在某些情况下可以在 EL1 上执行任意指令;更高的特权等级就不行了。因为 root 用户是操作系统的概念,因此 root 权限顶多是操作系统中的最高权限;在我们的类 Unix 系统中,它仅能触及 EL1 也就不算奇怪了。
对于内存、闪存以及各种外设来说,它们一般由操作系统内核和驱动来管理,而内核和驱动运行的指令通常位于 EL1,因此,root 权限意味着对所有的硬件(不包括 TEE 相关硬件)和外设拥有完全的控制权。
总结一下就是,root 权限所拥有的最高权限,是我们的用户操作系统能管理的所有权限,包括各种硬件和外设以及一部分 CPU 指令的执行权限。
把权力关进笼子里
在过去的很长一段时间里,root 用户拥有的 root 权限代表着最高权限,它能实施一切特权行为;然而,这种模式有着相当大的安全风险。比如说,如果一个 root 用户执行了 rm -rf / 命令(这种情况时有发生),那么整个系统就会瘫痪。
可以看出,直接把最高权限暴露给用户并不明智;本着把权力关进笼子里的原则,root 用户所拥有的 root 权限逐渐被加上了各种限制;从此以后,root 权限并不能为所欲为了。
SELinux
SELinux 可能是最常见的一种权限控制手段。很多童鞋在刷机或者用框架的时候,会听到诸如「关闭 SELinux」,「开启宽容模式」,实际上就是对 SELinux 的控制。
传统的权限控制是通过自主访问控制实现的,所谓「自主」指的是,这个文件的所有者主动决定哪些其他的用户可以访问它所拥有的文件。一般通过文件权限码和访问控制表来实现。我们通常所说的,文件可读可写可执行,就是文件权限码,除了 rwx 以外,SUID/SGID 也是常见的权限码,它代表某个程序在被 execve 之后会自动切换其 EUID。而访问控制表(ACL)是一种补充手段,它可以实施更加精细的自主访问控制,感兴趣的可以参考 Linux 中的访问控制列表 [1]。
由于自主访问控制是「自主的」,如果某个用户无意中实施了错误操作(如 rm -rf /),那么整个系统就不受控了,因此强制访问控制 (MAC) 应运而生,而 SELinux 则是 MAC 的一种具体实现。
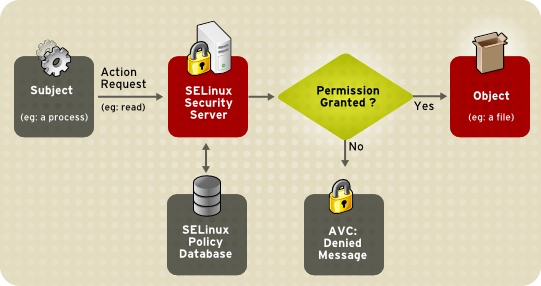
所谓强制访问控制,就是每当主体 (通常是进程)尝试访问对象(文件)时,都会由操作系统内核强制施行授权规则,由这些特殊的规则来决定是否授予权限;这些规则是独立于文件权限码之外的,因此,即使某个用户(如 root)是某个文件的所有者,通过这些额外的规则,可以让这个用户无法对这个文件执行某些操作。
通常情况下,root 用户也有权限关闭 SELinux 的部分功能(如开启宽容模式),这种情况下 SELinux 的大部分机制会失效,使得 root 用户可以避开 SELinux 的限制。而我们所使用的一些 root 技术实现(如 Supersu, Magisk 等),会给 SELinux 系统添加一些特殊的规则,可以在不关闭 SELinux 的条件下,让我们的 root 用户绕过 SELinux 的限制,进而拥有传统意义上的超级权限。
在现代的 Android 系统中,如果 root 用户不幸运行在 SELinux Enforcing 状态下,而系统又没有为其开绿灯(定义特殊规则),那么它所能做的操作相当有限,某种程度上甚至连普通用户都不如,表现起来就像是个「残废」。
capabilities
除了强制访问控制以外,实际上 Linux 系统中还有一些其他的机制来限制超级权限。
在传统的权限控制中,系统一刀切地把权限分为超级权限 (privileged) 和普通权限(unprivileged),特权用户可以绕过所有的系统限制,而普通用户则受限于其权限位;这种方式有着明显的缺陷:如果普通用户想要执行某一个特殊操作,那它只能切换到特权用户,然而一旦切换到特权用户,它就拥有了所有的特殊权限;那么恶意用户就可以挂羊头卖狗肉,表面上说我只是想读个文件,结果切换到特权用户之后直接把你其他重要东西删了。
因此,Linux 系统引入了 capabilities 机制,这种机制把超级权限划分为若干种权限,按照需要给普通用户分配,很好地解决了一刀切的问题。比如说 CAP_NET_ADMIN 定义了与各种网络操作相关的权限,CAP_SETUID 定义了用户是否可以任意改变自己的 uid;这些不同的 capabilities 可以组合起来形成某个权限范围,从而实现权限的细分。更多的 capabilities 可以参考 Linux man page[2] 和 linux-capabilities-in-a-nutshell[3]。
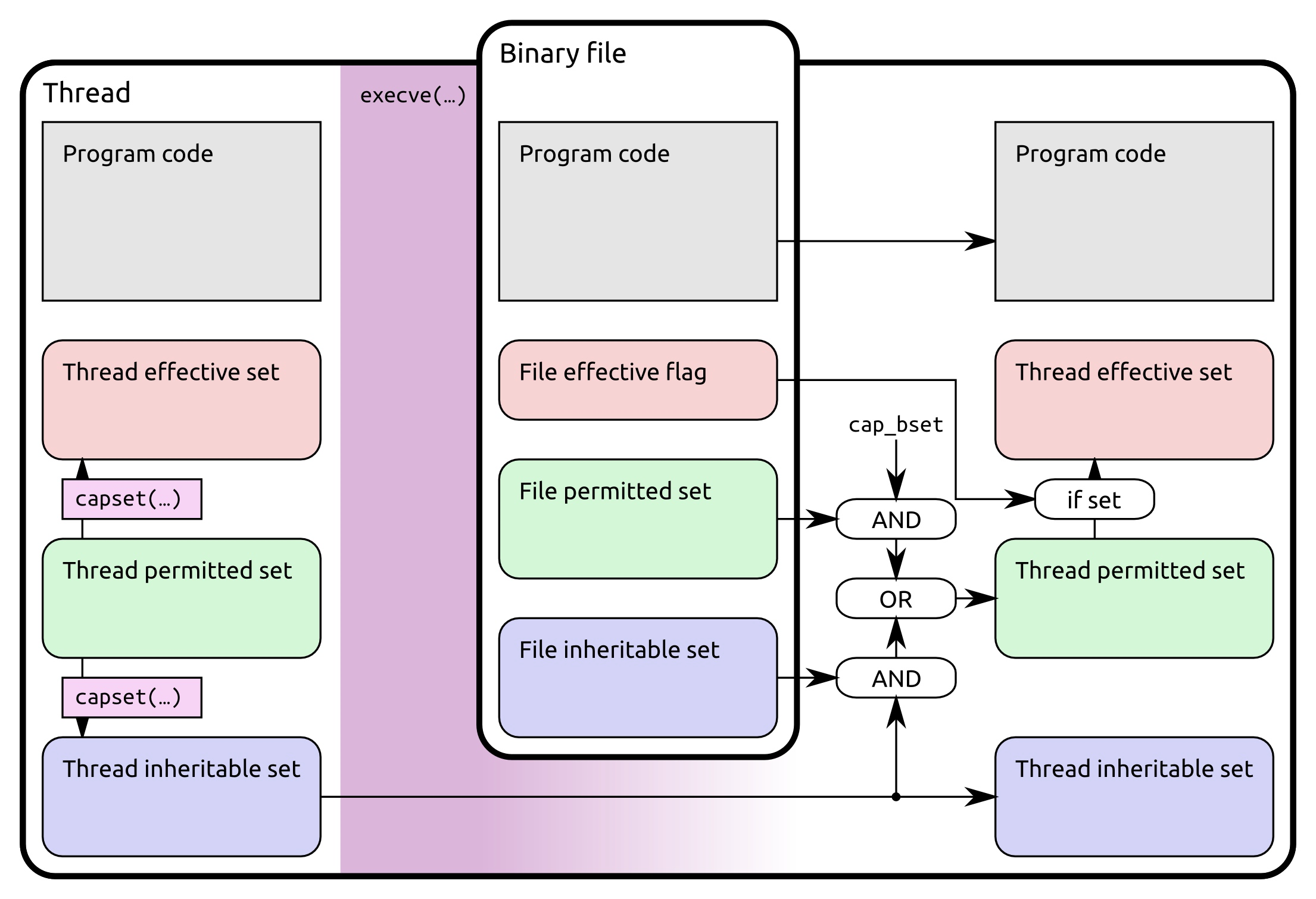
我们在实现某些 root 机制的时候,如果没有处理好 capabilities 的问题,就会出现各种类似残废 root 的情况,比如 root 用户无法访问网络等。
seccomp
严格来讲,seccomp 并不算是一种安全策略,不过这种机制也能对我们的 root 用户实施某些限制;这里也简单滴介绍一下。
seccomp 是 secure computing mode[4] 的缩写,它是内核的一种安全计算机制,这种机制可以对进程能执行的系统调用(与内核打交道的机制)做出一些限制。
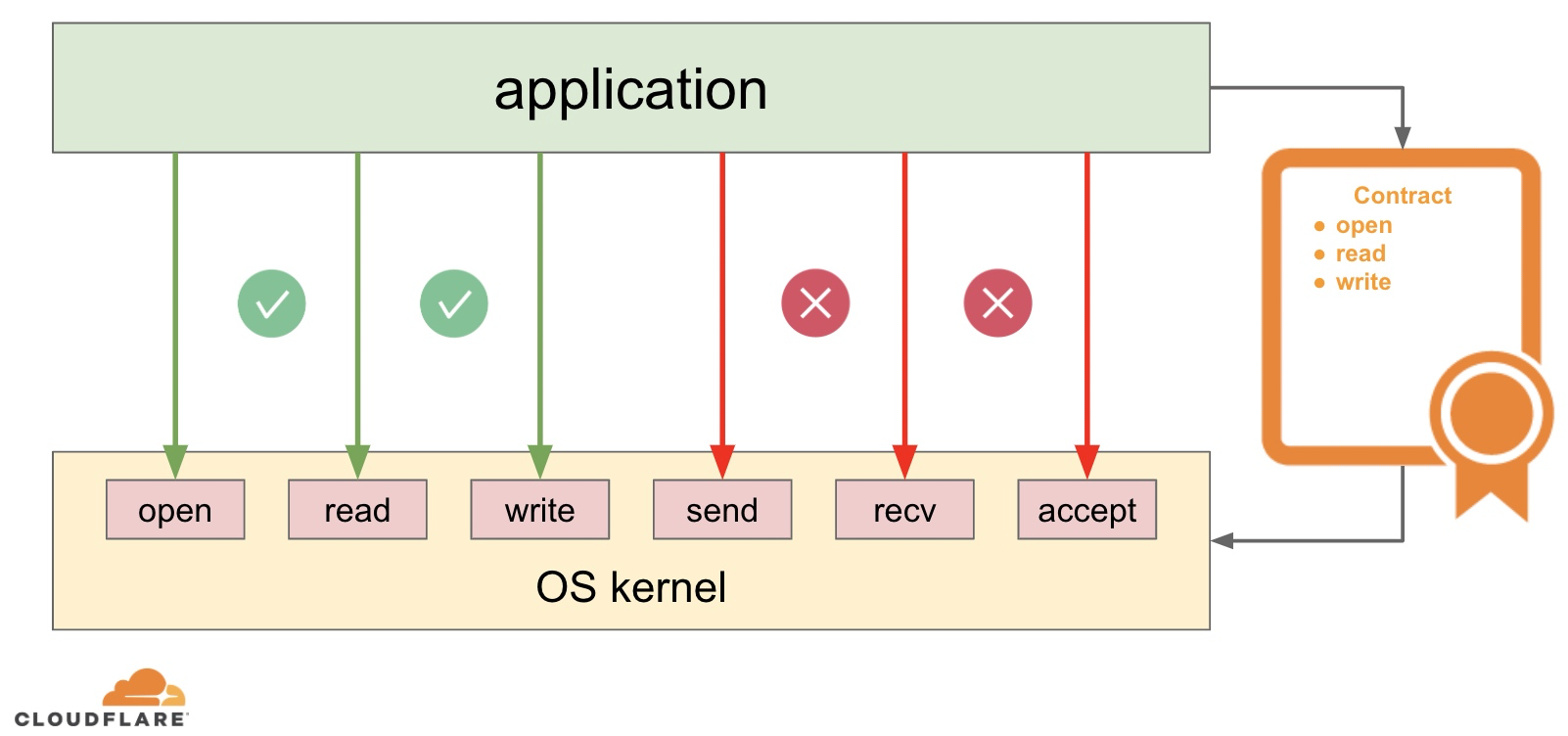
在传统的 seccomp 中,某个进程可以通过这种机制进入一种不可逆转的状态,在这种状态下,它只能执行 exit, sigreturn, read, write 这几个系统调用;后来人们发现对进程的系统调用添加限制还挺有用,于是拓展了 seccomp,让它可以通过某种自定义的策略来限制特定的系统调用(而不是写死的 exit,read 那几个),也就是 seccomp-bpf。
与 capabilities 类似,如果某种 root 机制没有处理好 seccomp 的问题,同样会出现「残废 root 的情况。
内核模块加载验证
我们前面提到,在 AArch64 中,操作系统内核运行在 CPU 的 EL1 特权模式中;然而,我们通常所使用的 root 机制并不能让我们任意地在 EL1 中执行指令,也就是说,我们现在用到的 root 机制,实际上是 EL0 root。
在 Linux 内核中,root 用户可以通过一种被称之为可加载内核模块(LMK)的机制来在内核空间(EL1 级别)执行代码。简单来说,就是写一个内核模块,然后通过 insmod 或者 modprob将此模块动态注册到内核之中执行;这样我们的 root 用户实际上就拥有了 CPU 的 EL1 执行权限。
然而不幸的是,现代 Android 系统对内核模块加载通常有验证机制,它不允许任意加载模块。通常的验证方式有两种:
1.vermagic 验证 2. 签名验证
vermagic 验证是因为 Linux 不保证内核模块的跨版本兼容性,因此在某个内核版本编译出来的模块被禁止在另外一个版本上运行;它通过内核版本号和导出符号的布局来限制模块的加载,避免出现模块和内核间不同版本的兼容性问题。
签名验证就是一种纯粹的安全机制,在开启这个机制之后,内核拒绝加载未经验证过的签名的模块;与解锁 Bootloader 一样,这个签名通常在设备制造商手里,第三方签名的模块无法被加载。
简单来说,内核模块加载验证机制在某种程度上阻止了我们对 EL1 级别权限的获取,目前我们所使用的 root 实现被限制在 EL0,无法实现更高级别的特权操作。
实现 root 访问的方法
前面我们描述了 root 权限所能执行的操作和为了限制超级权限做出的一些特殊机制,那么,在 Android 系统中,我们如何获取 root 权限呢?
实现 root 的方式整体上可以分为两种:
- 解锁 Bootloader,通过修改 Android 系统的某一部分实现 root。2. 通过某些系统漏洞提取,进而获取 root 权限。
我们在前文 [5] 可以知道,解锁 Bootloader 实际上就允许我们刷入第三方或者被修改过的操作系统;如果我们可以解锁 Bootloader,那么理论上讲我们就可以任意修改其操作系统,而 root 权限只不过是操作系统的某种机制,因此获取 root 权限自然不在话下。而这种修改方式常见的如下:
- 通过直接刷入第三方系统实现;在这个第三方系统中,系统自带 root 权限。2. 通过修改原系统的
init实现;因为 init 进程是 Linux 系统的第一个进程,因此它实际上就以 root 身份执行的;通过修改 init 也可以实现 root 访问;Magisk 就是通过代理 init 实现的 root 权限。3. 通过自定义内核实现;因为 root 权限实际上是内核操控的,因此自定义内核然后刷入自然可以获取 root 权限。
如果我们不能解锁 Bootloader,那么可以通过系统漏洞来提权,进而拥有 root 权限。在远古时代(特别是 Android 6.0 以前),各种一键 root 满天飞,比如 kingroot,360 一键 root,他们本质上都是通过系统漏洞来获取特殊权限;然而,随着 Android 系统的演进,这种通过漏洞提权获取 root 的方式已经很难出现在普通的大众视野里面了。我曾经提到太极有一种「少阳」模式,它就是通过这种方式来提权,进而实现不解锁就能对系统进程加载模块的;然而由于这种方式实际上就是利用漏洞,从机制上讲并不长久,因此被永久雪藏。
如果我们通过系统漏洞提权,那么必须妥善处理好我上面所介绍的各种限制,如绕过 SELinux,关闭 seccomp,获取所有 capabilities,否则提权之后的 root 基本就是个残废;然而,绕过这所有的机制并无一个稳定可用的方法,再加上 Android 系统的碎片化,导致通过漏洞获取通杀 root 权限的实现成本变得非常之高。
root 的过去和现在
上面我们介绍了一些 root 权限的获取方式,那么具体来说,从 Android 诞生到现在,我们实际上所使用的 root 方案,具体是哪种机制呢?
在 Android 系统的远古时代,root 方案基本上是通过 SUID 实现的。在上文描述 capabilities 和自主访问控制的时候我们提到过这种机制。SUID[6] 是一个特殊的权限位,它的特殊之处在于,如果某个可执行文件设置了这个权限位,某个用户在执行这个文件的之后,启动进程的 uid 会被自动切换为文件所有者的 uid。
打个比方,假设我有个文件名叫 su,它的所有者是 root,其他进程有其可执行权限;如果没有设置 SUID,那么某个进程比如 uid 为 10000,在执行这文件之后,它启动的进程实际 uid 也是 10000,也就是一个普通进程;而如果这个文件有被设置 SUID 位,那么 uid 为 10000 的用户在执行这个文件之后,所启动的进程 uid 会被自动切换为文件所有者,也就是 root 用户,这个进程就是一个特权进程。
用这种方式实现 root 可谓是非常简单,只需要丢一个 SUID 的文件到系统里面就结束了。然而,Android 4.3 系统的安全性改进 [7] 让这种机制退出了历史舞台。这种机制其实非常简单,就是通过我们上文提到的 capabilities 机制,给 zygote 的子进程限制了 CAP_SETUID;而我们的 Android App 都是 zygote 子进程,因此 App 从此与 SUID root 告别了。然而,我们的 shell 用户还是可以 SUID 的;某些系统中自带的 su 还是这种 SUID 的 root,在这种系统中我们会发现,adb shell 可以获取 root 权限,但是 App 进程死活无法获取 root,这时候可以看一下 su 文件是否有 SUID 位,如果有的话就是这个原因。
在没有 SUID 之后,App 进程是无法 fork 一个 uid 为 0 的子进程的;从此以后,我们常见的 root 实际上是一种「远程 root 进程」。
因为我们的 App fork 出来的进程 uid 不能被改为 0,因此这个进程肯定无法变成 root 进程,怎么办呢?我们可以启动一个远程的特权进程,这个进程的 uid 是 0(比如从 init fork 出来),一旦我们的 App 需要使用 root,那就从 App fork 出一个子进程,让这个子进程与那个远程的特权进程关联起来,我们想要执行 root 命令的时候,还是与以前一样让这个子进程去做,不同的是,这个子进程实际上并不会执行这些命令,而是把命令发给那个远程的特权进程让它去执行,特权进程执行完毕之后把结果再返回给子进程,这样也实现了我们所需要的 root 访问。你可以简单地把我们 fork 出来的子进程当作那个远程特权进程的代理,所以我把这种方式称之为「远程 root 进程」。现在的 Supersu 和 MagiskSU 都是通过这种方式实现的,如果你在 Magisk 下执行一个 root 命令,你会发现除了你自已的 su 进程之外,还会有一个 magiskd 的进程,这两个进程会通过 UDS(Unix Domain Socket) 通信,有很多 Magisk 检测手段就是通过检测 UDS 实现的。
root 的未来
从上文我们可以了解到,当前的各种 root 实现本质上都是 EL0 root。由于这种 root 的实现机制本质上运行在用户空间,它始终有其局限性;
我们需要一个 EL1 root!
我认为,随着 GKI 的出现 [8],内核的碎片化会逐渐消失,我们完全可以通过修改内核的方式去获取 EL1 root。
无比期待这种新的 root 方式的到来。
后记
本文酝酿了很久,现在终于写完了,如释重负!如果不当之处或者技术性错误,还请海涵!
但愿能帮到大家,晚安!
References
[1] Linux 中的访问控制列表: https://documentation.suse.com/zh-cn/sled/15-SP2/html/SLED-all/cha-security-acls.html
[2] Linux man page: https://man7.org/linux/man-pages/man7/capabilities.7.html
[3] linux-capabilities-in-a-nutshell: https://k3a.me/linux-capabilities-in-a-nutshell/
[4] secure computing mode: https://en.wikipedia.org/wiki/Seccomp
[5] 前文: https://mp.weixin.qq.com/s?__biz=MjM5Njg5ODU2NA==&mid=2257498934&idx=1&sn=18a65d736b6b9f5870d15de19709924e
[6] SUID: https://en.wikipedia.org/wiki/Setuid
[7] Android 4.3 系统的安全性改进: https://source.android.com/security/enhancements/enhancements43
[8] GKI 的到来: https://source.android.com/devices/architecture/kernel/generic-kernel-image

Comments | NOTHING