



FFmpeg 简介
被称为 “多媒体技术领域的瑞士军刀”,FFmpeg 拥有广泛的应用基础。不过,当(实时)处理海量视频时,需要借助各种方法提升效率。比如,短视频平台 Revvel 将视频转码服务迁移到 AWS Lambda 和 S3 上,节省了大量费用和运维成本,并且将时长 2 小时的视频转码从 4-6 小时缩短到不到 10 分钟。
多媒体应用程序是典型的资源密集型应用,因此优化多媒体应用程序至关重要,这也是使用视频处理专用硬件加速的初衷。作为回报,这允许整个系统更加有效地运行(以达到最佳性能)。 但是为了支持硬件加速,软件开发厂商面临着各种挑战:一个是存在潜在的系统性能风险问题;此外,软件开发商一直也因为要面对各种硬件架构的复杂性而苦苦挣扎,并需要维护不同的代码路径来支持不同的架构和不同的方案。优化这类代码,耗时费力。想想你可能需要面对不同的操作系统,诸如 Linux,Windows,macOS,Android,iOS,ChromeOS;需要面对不同的硬件厂商,诸如 Intel,NVIDIA,AMD,ARM,TI, Broadcom……,因此,提供一个通用且完整的跨平台,跨硬件厂商的多媒体硬件加速方案显得价值非凡。
专用视频加速硬件可以使得解码,编码或过滤(Filter)等操作更快完成且使用更少的其他资源(特别是 CPU),但可能会存在额外的限制,而这些限制在仅使用软件 CODEC 时一般不存在。在 PC 平台上,视频硬件通常集成到 GPU(来自 AMD,Intel 或 NVIDIA)中,而在移动 SoC 类型的平台上,它通常是独立的 IP 核(存在着许多不同的供应商)。硬件解码器一般生成与软件解码器相同的输出,但使用更少的 Power 和 CPU 来完成解码。另外,各种硬件支持的 Feature 也各不相同。对于具有多种不同 Profile 的复杂的 CODEC,硬件解码器很少实现全部功能(例如,对于 H.264,硬件解码器往往只支持 8bit 的 YUV 4:2:0)。
许多硬件解码器的一个共同特点是能够输出硬件 Surface,而该 Surface 可以被其他组件进一步使用(使用独立显卡时,这意味着硬件 Surface 在 GPU 的存储器中,而非系统内存) ,对于播放(Playback)的场景,避免了渲染输出之前的 Copy 操作;在某些情况下,它也可以与支持硬件 Surface 输入的编码器一起使用,以避免在转码(transcode)情况下进行任何 Copy 操作。另外,通常认为硬件编码器的输出比 x264 等优秀软件编码器质量差一些,但速度通常更快,且不会占用太多的 CPU 资源。也就是说,他们需要更高的比特率来使输出相同的视觉感知质量,或者他们以相同的比特率以更低的视觉感知质量输出。具有解码和 / 或编码能力的系统还可以提供其他相关过滤(Filter)功能,比如常见的缩放(scale)和去隔行(deinterlace);其他后处理(postprocessing)功能可能取决于系统。
FFmpeg 所支持的硬件加速方案,粗略以各 OS 厂商和 Chip 厂商特定方案以及行业联盟定义的标准来分为 3 类;其中,OS 涉及 Windows,Linux,macOS,Android;Chip 厂商的特定方案涉及到 Intel,AMD,Nvidia 等;而行业标准则着重 OpenMAX 与 OpenCL ;这只是一个粗略的分类,很多时候,这几者之间纵横交错,联系繁杂,之间的关系并非像列出的 3 类这般泾渭分明;这从另一个侧面也印证了硬件加速方案的复杂性。就像我们熟知的大部分事情一样,各种 API 或解决方案一面在不断的进化同时,它们也背负着过去的历史,后面的分析中也可以或多或少的窥知其变迁的痕迹。
- 基于 OS 的硬件加速方案
- Windows:Direct3D 9 DXVA2 /Direct3D 11 Video API/DirectShow /Media Foundation
大多数用于 Windows 上的多媒体应用程序都基于 Microsoft DirectShow 或 Microsoft Media Foundation(MF)框架 API,用他们去支持处理媒体文件的各种操作;而 Microsoft DirectShow Plug in 和 Microsoft Foundation Transforms(MFT)均集成了 Microsoft DirectX 视频加速(DXVA)2.0,允许调用标准 DXVA 2.0 接口直接操作 GPU 去 offload Video 的负载(workload)。
DirectX 视频加速(DXVA)是一个 API 和以及需要一个对应的 DDI 实现,它被用作硬件加速视频处理。软件 CODEC 和软件视频处理器可以使用 DXVA 将某些 CPU 密集型操作卸载到 GPU。例如,软件解码器可以将逆离散余弦变换(iDCT)卸载到 GPU。 在 DXVA 中,一些解码操作由图形硬件驱动程序实现,这组功能被称为加速器( accelerator);其他解码操作由用户模式应用软件实现,称为主机解码器或软件解码器。通常情况下,加速器使用 GPU 来加速某些操作。无论何时加速器执行解码操作,主机解码器都必须将包含执行操作所需信息的加速器缓冲区传送给加速器缓冲区。
DXVA 2 API 需要 Windows Vista 或更高版本。为了后向兼容,Windows Vista 仍支持 DXVA 1 API(Windows 提供了一个仿真层,可在 API 和 DDI 的版本之间进行转换;另外,由于 DAVX 1 现在存在的价值基本上是后向兼容,所以我们略过它,文章中的 DXVA,大多数情况下指的实际上是 DAVA2)。为了使用 DXVA 功能,基本上只能根据需要选择使用 DirectShow 或者 Media Foundation;另外,需要注意的是,DXVA/DXVA2/DXVA-HD 只定义了解码加速,后处理加速,并未定义编码加速,如果想从 Windows 层面加速编码的话,只能选择 Media Foundation 或者特定 Chip 厂商的编码加速实现。现在,FFmpeg 只支持了 DXVA2 的硬件加速解码,DXVA-HD 加速的后处理和基于 Media Foundation 硬件加速的编码并未支持(在 DirectShow 时代,Windows 上的编码支持需要使用 FSDK)。
下图展示了基于 Media Foundation 媒体框架下,支持硬件加速的转码情况下的 Pipeline:
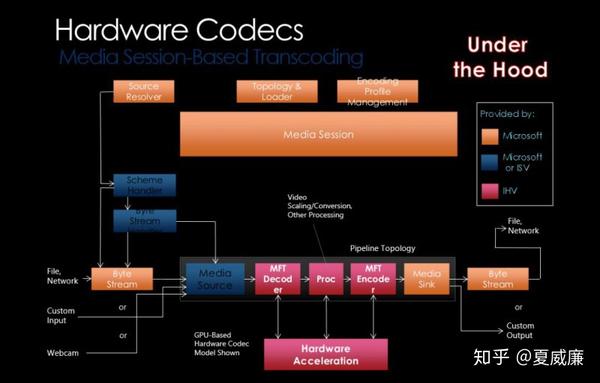
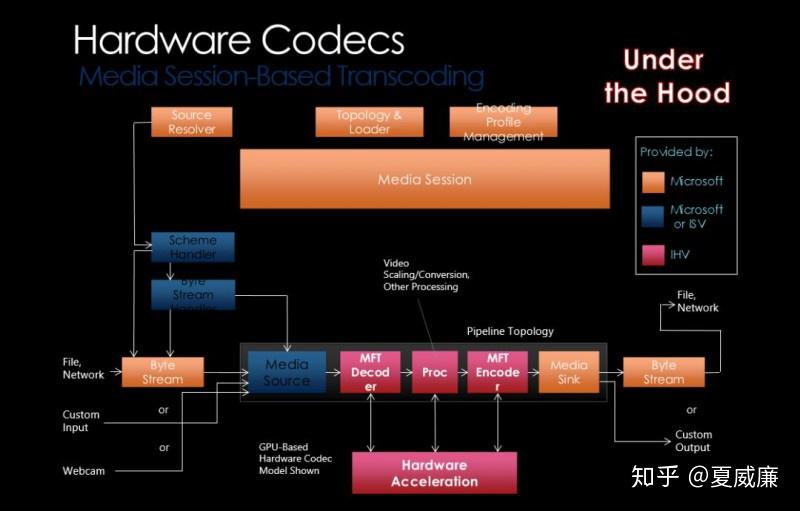
注意,由于微软的多媒体框架的进化,实际上,现在存在两种接口去支持硬件加速,分别是:Direct3D 9 DXVA2 与 Direct3D 11 Video API; 前者我们应该使用 IDirect3DDeviceManager9 接口作为加速设备句柄, 而后者则使用 ID3D11Device 接口。
对于 Direct3D 9 DXVA2 的接口,基本解码步骤如下:
- Open a handle to the Direct3D 9 device.
- Find a DXVA decoder configuration.
- Allocate uncompressed Buffers.
- Decode frames.
而对于 Direct3D 11 Video API 接口,基本解码步骤如下:
- Open a handle to the Direct3D 11 device.
- Find a decoder configuration.
- Allocate uncompressed buffers.
- Decode frames.
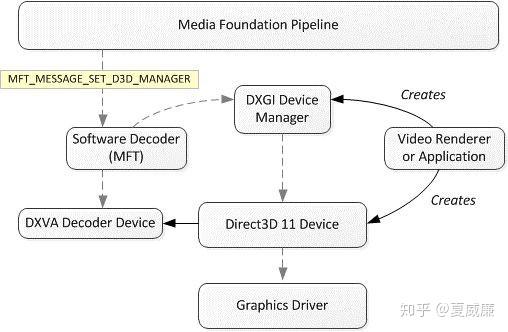
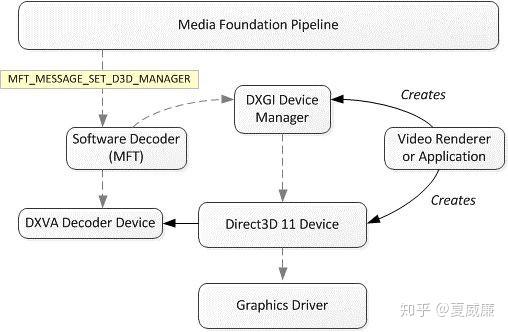
在微软网站上,上述两种情况都有很好的描述,参考链接在:https://msdn.microsoft.com/en-us/library/windows/desktop/cc307941(v=vs.85).aspx。
从上面可以看到,实际上,FFmpeg 基于 Windows 上的硬件加速,只有解码部分,且只使用了 Media Foundation 媒体框架,只是同时支持了两种设备绑定接口,分别是 Direct3D 9 DXVA2 与 Direct3D 11 Video API。
- Linux:VDPAU/VAAPI/V4L2 M2M
Linux 上的硬件加速接口,经历了一个漫长的演化过程,期间也是各种力量的角力,下面的漫画非常形象的展示了有关接口的演化与各种力量的角力。


最终的结果是 VDPAU(https://http.download.nvidia.com/XFree86/vdpau/doxygen/html/index.html)与 VAAPI(https://github.com/intel/libva)共存这样一个现状,而这两个 API 其后的力量,则分别是支持 VDPAU 的 Nvidia 和支持 VA-API 的 Intel,另一个熟悉的 Chip 厂商 AMD,实际上同时提供过基于 VDPAU 和 VA-API 的支持,真是为难了他。
另外,对照 VDPAU 与 VA-API 可知,VDPAU 仅定义了解码部分的硬件加速,缺少了编码部分的加速(解码部分也缺乏 VP8/VP9 的支持,且 API 的更新状态似乎也比较慢),此外,值得一提的是,最新的状态是,Nvidia 似乎是想用 NVDEC 去取代提供 VDPAU 接口的方式去提供 Linux 上的硬件加速(https://www.phoronix.com/scan.php?page=news_item&px=NVIDIA-NVDEC-GStreamer),或许不久的将来,VA-API 会统一 Linux 上的 Video 硬件加速接口(这样,AMD 也不必有去同时支持 VDPAU 与 VAAPI 而双线作战的窘境),这对 Linux 上的用户,无疑可能是一个福音。除去 VDPAU 和 VAAPI,Linux 的 Video4Linux2 API 的扩展部分定义了 M2M 接口,通过 M2M 的接口,可以把 CODEC 作为 Video Filter 去实现,现在某些 SoC 平台下,已经有了支持,这个方案多使用在嵌入式环境之中。
下图展示了 VA-API 接口在 X-Windows 下面的框图以及解码流程:
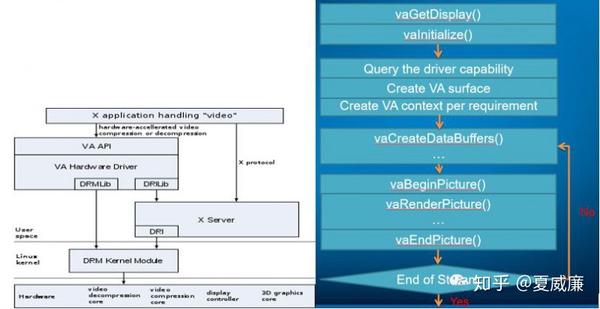
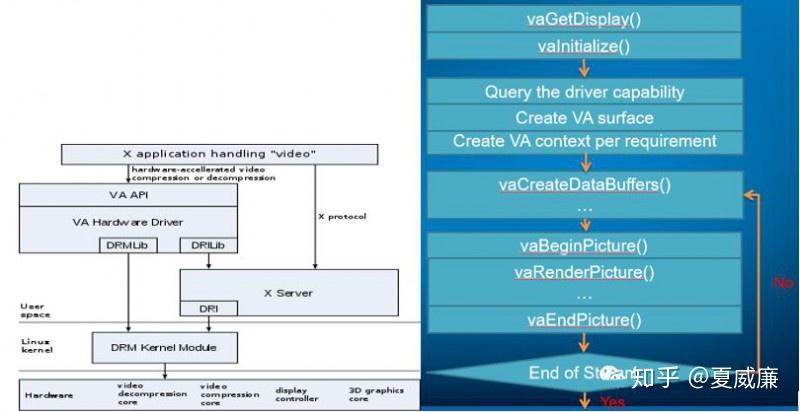
FFmpeg 上,对 VA-API 的支持最为完备,基本上,所有主流的 CODEC 都有支持,DECODE 支持的细节如下:
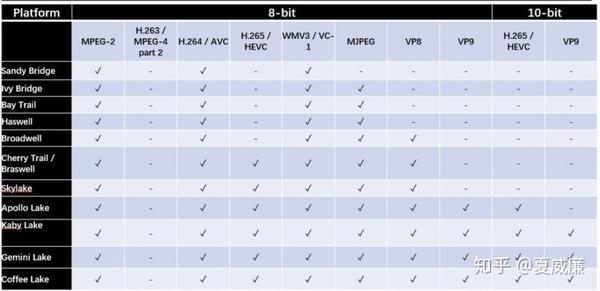
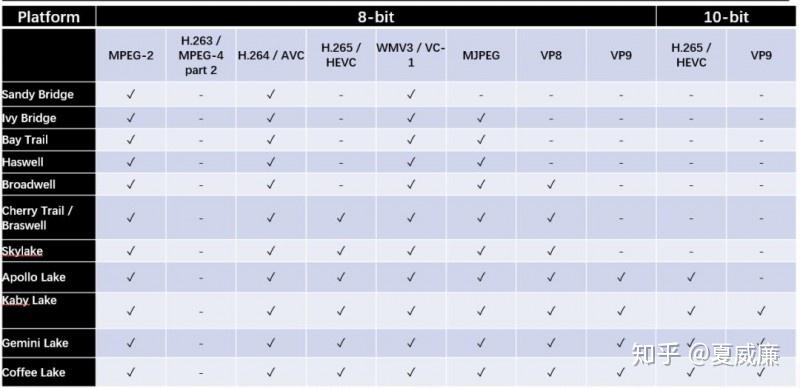
ENCODE 支持的细节如下:
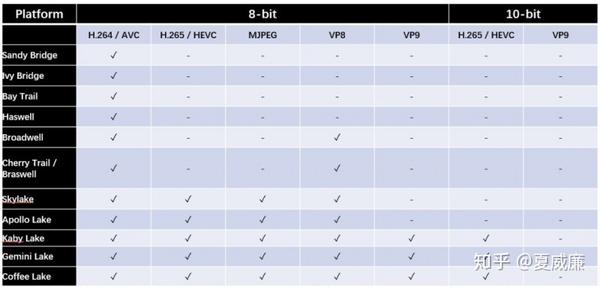
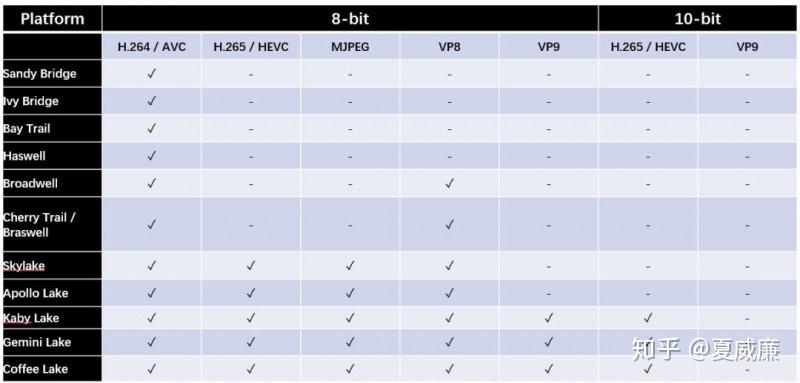
在 AVFilter 部分也同时支持了硬件加速的 Scale/Deinterlace/ ProcAmp(color balance) Denoise/Sharpness,另外,我们在前面提及过,FFmpeg VAAPI 的方案中,不只是有 Intel 的后端驱动,同时,它也可以支持 Mesa's state-trackers for gallium drivers,这样,其实可以支持 AMD 的 GPU。
- macOS: VideoToolbox
在 macOS 上的硬件加速接口也是跟随着 Apple 经历了漫长的演化,从 90 年代初的 QuickTime 1.0 所使用的基于 C 的 API 开始,一直到 iOS 8 以及 OS X 10.8,Apple 才最终发布完整的 Video Toolbox framework(之前的硬件加速接口并未公布,而是 Apple 自己内部使用),期间也出现了现在已经废弃的 Video Decode Acceleration (VDA) 接口。Video Toolbox 是一套 C API ,依赖了 CoreMedia, CoreVideo, 以及 CoreFoundation 框架 ,同时支持编码,解码,Pixel 转换等功能。Video Toolbox 所处的基本层次以及更细节的相关结构体如下:


关于 Video Toolbox 的更多细节,可以参考 https://developer.apple.com/documentation/videotoolbox。
参考文献
- https://trac.ffmpeg.org/wiki/HWAccelIntro,FFmpeg 的网站上对硬件加速的信息,是首要阅读的文档
- Supporting DXVA 2.0 in Media Foundation 微软的 msdn,讲解了如何在 Media Foundation 中支持 DXVA2, 里面讲的是如何绑定 Direct3D9 device
- Supporting Direct3D 11 Video Decoding in Media Foundation 另一份 msdn 文档,讲的是 Media Foundation 中如何使用 Direct3D 11 去支持 DXVA2
- 有关标准的漫画,出自 https://xkcd.com/927/
- https://wiki.archlinux.org/index.php/Hardware_video_acceleration 和 https://wiki.ubuntu.com/IntelQuickSyncVideo Archlinux 和 Ubuntu 网站对 VDPAU 和 VA-API 后端驱动的支持,虽然内容有些过时,但仍然颇值得参考
- https://trac.ffmpeg.org/wiki/Hardware/VAAPI 和 https://wiki.libav.org/Hardware/vaapi 如果你忘了怎么在 FFmpeg 命令行使用 VA-API, 这两个地方是你最应该看看的
- Video Toolbox and Hardware Acceleration 里面详细讲解了 macOS 平台上,硬件加速框架的演化还有 Video Toobox 的技术细节,与之对应的是 WWDC2014 上的 https://developer.apple.com/videos/play/wwdc2014/513/ 也值得一读
- https://github.com/intel/libva VA-API 的接口定义甚至没有正规的文档,好在头文件里面的注释还写得非常清楚,这也是典型开源项目的风格吧
Android: MediaCodec
MediaCodec 是 Google 在 Android API 16 之后推出的用于音视频编解码的一套偏底层的 API,可以直接利用硬件以加速视频的编解码处理。MediaCodec 的概念中,一般而言,编解码器处理输入数据并生成输出数据。它异步处理数据并使用一组输入和输出缓冲区。在简单的层面上,需要请求(或接收)一个空输入缓冲区,填充数据并将其发送到编解码器进行处理。编解码器使用数据并将其转换为其空的输出缓冲区之一。最后,你请求(或接收)一个填充的输出缓冲区,消耗其内容并将其释放回编解码器。
MediaCodec 可以处理的数据有以下三种类型:被压缩的 Buffer(Compressed Buffers)、原始音频数据 (Raw Audio Buffers)、原始视频数据 (Raw Video Buffers)。可以使用 ByteBuffers 处理所有三种数据,但一般应该使用 Surface 以提高编解码器的性能。 Surface 使用本地视频缓冲区,无需映射或复制到 ByteBuffers; 因此,效率更高。 通常在使用 Surface 时无法访问原始视频数据,但可以使用 ImageReader 类来访问不安全的解码(原始)视频帧。 这可能比使用 ByteBuffers 更有效率,因为一些本机缓冲区可能被直接映射到 ByteBuffers。 当使用 ByteBuffer 模式时,也可以使用 Image 类和 getInput / OutputImage(int)访问原始视频帧。FFmpeg 自 3.1 版本加入了 android MediaCodec 硬件解码支持,其实现 Follow 了 FFmpeg 的 HWaccel 接口,但直到现在为止,FFmpeg 都并未支持基于 MediaCodec 的硬件加速编码。
1.基于 Chip 厂商的私有方案
这里所提及的私有,并非是说代码没有 Open,更多层面上是指所提供的相应的 API 接口和实现,是厂商所特定的,而非行业标准定义的 API ,诸如 OpenMAX 或者 OS 层面剥离了硬件具体实现相关抽象的 API。更进一步说,是采用相关厂商私有方案之后,如果想要二次深度开发,其困难度较大一些。实际上,从开放的角度而言,Intel,AMD,Nvidia 这 3 家 GPU 大厂所提供的方案的 Open 程度不尽相同,总的说来,其开放程度是 Intel 好于 AMD, 而 AMD 又好于 Nvidia。
Intel: Media SDK:
Intel 提供的 Media SDK,本质是一套跨平台的加速方案,它在 Windows/Linux 上提供了相同的 API,底层则分别使用了 Windows 上的 DXVA2 和 Linux 上的 VAAPI 接口,以 Windows 平台上为例,它的基本结构框图如下:
而在 FFmpeg 的集成中,基本上是在 Libavcode/Libavfilter 内提供了一个基本的 wrapper 去调用 Media SDK 的 API 来提供相应的功能。下图展示了 Libavcodec 集成 MediaSDK 的 h264/hevc/mpeg2 Codec 的状态,需要注意的是,FFmpeg master 开发分支上支持的 FFmpeg QSV 已经支持了更多的 Codec 和相关 VPP 功能。
在 Windows 平台,如果你想在 Intel 平台上执行编码相关的事务, Media SDK 基本上是唯一的选择。当然,如果你更偏向 FFmpeg 的 API,可以使用 FFmpeg QSV/Media SDK 的方式;而在 Linux 平台,FFmpeg VA-API 与 FFmpeg QSV/Media SDK 接口大部分功能重合,更多的区别可能在于软件灵活度和开放程度的考量。一般说来,FFmpeg VA-API 提供了更大的灵活度,对于有开发能力或者想二次定制的客户更加的友好一些。从 FFmpeg 的角度看,这两者在 FFmpeg 框架内的最大不同点在于: FFmpeg VA-API 是以 Native CODEC 的方式直接实现与 FFmpeg 内部,而 FFmpeg QSV 集成 Media SDK 的方式,非严格的类比则类似于 FFmpeg 集成 libx264 这样第三方库的方式,需要依赖 Media SDK,而 FFmpeg VA-API 则并不依赖第三方的库,其 CODEC 的实现直接位于 FFmpeg 代码库自身。另外,需要提及的另外一件事情是,Media SDK 开放了部分功能,其代码 Repo 在:
https://github.com/Intel-Media-SDK/MediaSDK
Nvidia: CUDA/CUVID/NVENC
之前提及 Nvidia 的时候说过,Nvidia 曾经一度提出 VDPAU 与 Intel 提出的 VA-API 在 Linux 上竞争,但最近的趋势似乎是 Nvidia 走向了更为封闭的方式,最主要的倾向是,Nvidia 似乎放缓了对 VPDAU 的支持,取而代之的是提供较为封闭的 NVDEC 与 NVENC 库。另外,在 FFmpeg 中集成 NVENC 与 NVDEC 的方式与 FFmpeg QSV 集成 Intel Media SDK 方式一致,也是以集成第三方库的方式集成进 FFmpeg 的。这带来的弊端是,对 NVENC/NVDEC 的依赖较大,加上 Nvidia 并未开放 NVENC/NVDEC 的代码,因此如果想做二次开发或者功能增强以及性能调整的时候,基本都得依赖 Nvidia 自身去改动 NVENC/NVDEC,这可能对部分开发者带来一些影响。
下面是 NVECN/NVDEC 说支持的 CODEC 的一个图示,基本上 FFmpeg CUVID/NVECN/CUDA 部分分别集成了硬件加速的解码,编码以及部分 CUDA 加速的诸如 Scaling 这样的 Filter。另外,CUVID 部分,为了和 NVENC 统一,Nvidia 已经把它改称为 NVENC,但 FFmpeg 并没有去做这个更新。
AMD: AMF
AMF SDK 用于控制 AMD 媒体加速器,以进行视频编码和解码以及色彩空间转换,现在开源出来的版本(https://github.com/GPUOpen-LibrariesAndSDKs/AMF),并未支持 Linux,只能在 Windows 上进行编码,支持的 Codec 有 AVC/HEVC。需要指出的是 AMF 的全称是 Advanced Media Framework,之前有时会被称之为 VCE(Video Coding Engine)
另外,VCE 实际上支持两种模式,一种模式是所谓的 full fixed mode,这种模式之下,所有的编码相关执行使用的 ASIC 方式,而另一种模式则是 hybrid mode,主要是通过 GPU 中的 3D 引擎的计算单元执行编码相关动作,而对应的接口则是 AMD's Accelerated Parallel Programming SDK 以及 OpenCL。
除了上述的一些方案以外,还有一些使用在嵌入式平台的一些方案,能够看到的有:
-
BRCM 的 MMAL:
-
RockChip:MPP
http://opensource.rock-chips.com/wiki_Mpp
http://opensource.rock-chips.com/images/f/fa/MPP_Development_Reference.pdf
-
TI DSP 方案:
有兴趣者,可以通过这些资源自行去获取相关信息。
2.独立于平台与 Chip 厂商的优化方案
OpenCL 与 Vulkan:
Khronos 在 OpenGL 的年代一战成名,最近这些年,围绕着高性能图形图像 API 提出了大量的标准,其中有两个较新的标准值得注意,一个是 OpenCL,最初是 Apple 提出,现在则是异构高性能并行计算的标准,其出发点基本是以 Nvidia 的 CUDA 为对标;另一个则是 OpenGL 的后继者 Vulkan。最新的动向是 Khronos 似乎打算把 OpenCL 标准整合进 Vulkan,所以很可能不久的将来,Vulkan 会变成统一图像与计算的 API。由于 OpenCL 基本上是 GPU 上编程的唯一通用标准(另一个业内使用范围更广泛的是 Nvidia 的 CUDA),很自然的 FFmpeg 也打算用 OpenCL 去加速相应的一些 Codec 或者 AVfiter 相关的任务。最初,x264 尝试用 OpenCL 优化,但结果并不尽理想,主要原因估计是很多时候编码器实现是一个反复迭代的过程,数据之间也会出现依赖,导致想完全并发利用 OpenCL 去加速,比较困难,所以最终 x264 只用 OpenCL 加速了部分功能,更多的信息可以参考
https://mailman.videolan.org/pipermail/x264-devel/2013-April/009996.html
FFmpeg 并未尝试用 OpenCL 去优化 Codec 部分,但是却优化了 AVFilter 部分,主要用在硬件加速转码的场景下。其最大的好处是解码,Filter、编码都在 GPU 内部完成,避免了 GPU 与 CPU 之间的数据交换,而一般 Codec 输出的数据,需要与 OpenCL 实现所谓的 Zero Copy,这一点,需要 OpenCL 做一些扩展以支持接收解码器解码的出来的数据格式,并输出编码器能接收的数据格式。这里典型的扩展如 Intel 提出的 OpenCL 与 VA-API 的 Surface sharing:
https://www.khronos.org/registry/OpenCL/extensions/intel/cl_intel_va_api_media_sharing.txt:
最近,FFmpeg 社区的 Rostislav Pehlivanov 开始尝试用 Vulkan 优化 AVFilter,已经提交了 Patch,正处于 Review 阶段,从他 FOSDEM 的 PPT https://pars.ee/slides/fosdem18_encoding.pdf 看,他似乎也想再次尝试用 Vulkan 来优化 Codec,但初期只有针对 AVFilter 的优化代码出现。顺带说一句,Rostislav Pehlivanov 的这份 PPT 中,回顾了各种 CODEC 上的各种尝试,整个行业在 CODEC 上的努力,而其中大部分的 CODEC,并未流行开来,但这些人的种种努力不该被完全忘记。
- 参考文献
-
https://developer.nvidia.com/nvidia-video-codec-sdk 更多 Nvidia video codec 的信息,可以从这里获取到
-
http://on-demand.gputechconf.com/gtc/2016/presentation/s6226-abhijit-patait-high-performance-video.pdf 这里对 NVENC/NVDEC 给出了一些详尽的说明
-
https://developer.android.com/reference/android/media/MediaCodec.html 使用 MediaCodec 时候,Android 上的文档基本上是必须要先读的
-
https://elinux.org/images/9/9d/Android_media_framework--van-dam_and_kallere.pdf
-
https://www.khronos.org/ khronos 最近动作不断,一方面,看到各种新标准的提出,另一方面又担心这些标准最终实施的状况。
WebRTCon 2018
WebRTCon 2018 将于 5 月 19-20 日在上海光大国际会展中心举行,这是一次对过去几年 WebRTC 技术实践与应用落地的总结。
大会组委会以行业难点为目标,设立了主题演讲,WebRTC 与前端,行业应用专场,测试监控和服务保障,娱乐多媒体开发应用实践,WebRTC 深度开发,解决方案专场,WebRTC 服务端开发,新技术跨界,WebRTC 与 Codec 等多个专场。邀请 30 余位全球领先的 WebRTC 技术专家,为参会者带来全球同步的技术实践与趋势解读。
在主题演讲环节,Google 软件工程师 Zoe Liu 、姜健,将分别向国内的开发者分享 AV1 的最新进展与技术探索、VP9 的 SVC 优化。此外,北京大学教授王荣刚、英特尔实时通信客户端架构师邱建林、Aupera 傲睿智存 CTO 周正宁将分别分享国产 Codec AVS2 的最新演进、H.264 的硬件编码优化,FPGA 加速 WebRTC 服务端和转码。上海交通大学图像通信与网络工程研究所副所长宋利会分享学术界在 Codec 优化的最新思路与尝试,他会介绍 AI、区块链和大数据赋能的 Codec。

Comments | NOTHING