



思路实现
播放器没什么好说的,我也是用的 PotPlayer。
虽然作者吃相,额,有些不雅(这人已经被钉在开源界的耻辱柱上了,前略,天国的 KMPlayer),不过近几年的 PotPlayer 对一般群众来说,各方面综合是最好用的(至少比大部分内置播放器好用吧)。
如果你是爱好影音播放的发烧友,「VLC 天下第一」「MPC-HC 是天」之类一套一套的肯定比我懂得多,也没必要搁这听我这个半吊子吹牛批。
重点就在直播源上了。
斗鱼
十分感谢
「lyntal 分享的现成接口」和「西恩赛斯提供的斗鱼解析 API」免去了我再写一遍爬虫的工作,虽然写轮子很爽,但重复劳动太多就不爽了
以及「【直播源综合教程】斗鱼直播真实地址解析,直播源抓取方法,自抓直播源分享长期有效」一文详细解释了斗鱼长期直播源的解析方式
首先我们访问https://web.sinsyth.com/lxapi/douyujx.x?roomid=斗鱼直播间房间号获得 json 格式的解析结果,如果房间未开播则返回:
本文大部分代码为了方便阅读已做格式化处理,可能与原始数据有出入,下同。
{
"type": "strjson",
"Rendata": {
"tname": "Unbroadcast",
"time": "当前时间戳"
},
"info": "Live broadcasting has been closed",
"state": "NO"
}
得,不用抓取了,抓了无法播放也没用。
如果房间是正常直播状态,则返回(用杨树直播间举个例子):
{"type":"strjson","Rendata":{"media_type":"live","data":{"vid":"703747","roomName":"\u5c0f\u6811\u82d7 \u65b0\u5e74\u5feb\u4e50\uff01\uff01(\uff3e\uff0d\uff3e)V","nickname":"\u4e3b\u64ad\u6768\u6811","avatar":"https:\/\/apic.douyucdn.cn\/upload\/avanew\/face\/201801\/30\/11\/e4a5a931f99fe8b6224d0fe1a54311cc_big.jpg?rltime","roomimg":"https:\/\/rpic.douyucdn.cn\/asrpic\/200128\/703747_2053.png\/dy1","roominfo":"\u65e5\u62f1\u4e00\u5352\u65e0\u6709\u5c3d\uff0c\u529f\u4e0d\u5510\u6350\u7ec8\u5165\u6d77 \u6bcf\u5929\u56db\u70b9\u76f4\u64ad \u5468\u4e09\u4f11\u606f"},"link":"http:\/\/hdl1a.douyucdn.cn\/live\/703747rziSwf5jUt_2000p.flv?wsAuth=dc8269b82ed106a0df2a093be9cecca2&token=cpn-androidmpro-0-703747-9df7fb858f23299ab8c9d917322c0ab70297c47401386b27&logo=0&expire=0&did=0921a95fc22478805d8c161bf3db6378&origin=all&vhost=play2","time":1580216008},"info":"Check-OK","state":"SUCCESS"}
这段有点长,格式化后用图片展示:
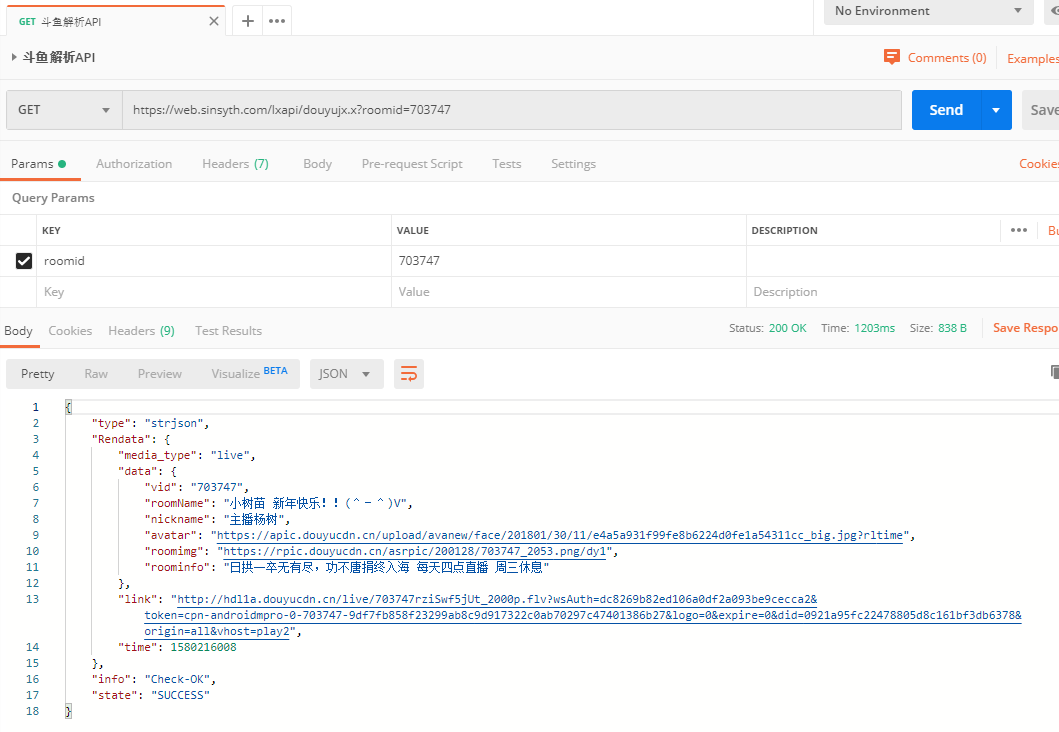
原数据中的中文是 unicode 编码,图中是转码后的结果。
可以看到包括主播名字 / 头像、直播间名字 / 公告 / 即时画面等信息。
我们需要的只是$response->Rendata->link这个字段的值,在本例中,就是
http://hdl1a.douyucdn.cn/live/703747rziSwf5jUt_2000p.flv?wsAuth=dc8269b82ed106a0df2a093be9cecca2&token=cpn-androidmpro-0-703747-9df7fb858f23299ab8c9d917322c0ab70297c47401386b27&logo=0&expire=0&did=0921a95fc22478805d8c161bf3db6378&origin=all&vhost=play2
这个 url(我这里贴出来的是转义后的结果,所以没有反斜杠了),就是时间加密后的临时直播源。
我们要做的是把他做成——不敢说永久——至少长期有效的直播源,免得没看一会又要重新抓取。
- 首先把
hdl1a(不一定是这个,也可能是hl1a或者别的什么,总之换掉它)这个加密后的二级域名替换成斗鱼的真实 cdn 域名tx2play1 - 找到
.flv?这个字段,截断它,后面是根据时间加密的参数,全部删掉 2000p是清晰度设置,2200 年了,还有谁家是 4M 小水管吗,没有吗,没有那就看原画,删掉它
长期直播源 get。
现在回顾一下,我们做了什么?
其实就是把中间.douyucdn.cn/live/703747rziSwf5jUt这段取出来,前面加上http://tx2play1,后面加.m3u8,拿直播源,就这么简单。(当然是建立在前人的成果上,再次感谢西恩赛斯提供的接口和 zhmxubing 提供的解析思路)
需要特别注意的一点,最后拿到的网址一定是 HTTP 而不是 HTTPS 协议。(只有 B 站的直播源是 HTTPS,有钱就是可以为所欲为)
虎牙
十分感谢
「虎牙直播源提取 / 分类 / 可选清晰度 / 开源 [更新] 」提供的思路(.e 源码是二进制真的秀,为了看源码我还专门装了易语言 5.8,进去一堆箭头把我看傻了)
然后我照着在服务器上用 PHP 实现了一遍,这里贴出来,有兴趣自行查看,没兴趣请跳过这段代码往下看,后来我找到了一种更便捷的方法。
//检测开播状态(通过直播间页面content暴力搜索唯一的state字段) 简单粗暴 不优雅 但有效
public function isHuyaLiving($room_id)
{
$curl = new Curl();
$curl->setOpt(CURLOPT_FOLLOWLOCATION, 1);
$curl->get("https://www.huya.com/" . $room_id);
$flag_content = ltrim(stristr($curl->response, "\"state\":\""), "\"state\":\"");
$curl->close();
return stristr($flag_content, "\"", true) == "ON" ? true : false;
}
//同理 获取整个直播间页面之后遍历内容
//下面整段代码只是为了抓取一万个接口中的一万条数据中的其中一条
//现在大家对「爬虫为什么这么吃资源」应该有形象的认识了
public function parseHuya($room_id)
{
if ($this->isHuyaLiving($room_id)) {
$curl = new Curl();
$curl->setOpt(CURLOPT_FOLLOWLOCATION, 1);
$curl->get("https://www.huya.com/" . $room_id);
$info_content = ltrim(stristr($curl->response, "var hyPlayerConfig = "), "var hyPlayerConfig = ");
$curl->close();
$json_str = stristr($info_content, "};", true) . "}";
$hyPlayerConfig = json_decode($json_str, true);
//抓取真实推流url
//注意 拿到的直播源是个数组 可能是为了有比赛时「同一直播间不同第一视角」那种需求
$streams = $hyPlayerConfig['stream']['data'][0]['gameStreamInfoList'];
//按理我们也应该用一个数组存 这里没用是暂时没那个需求 什么事都不可能一蹴而就的 先跑起来
$url = null;
//但处理还是当成数组处理的 方便以后二次开发
foreach ($streams as $k => $stream) {
//遍历所有直播源并处理成长期直播源
if ($stream['sCdnType'] == "AL") {
$url = $stream['sFlvUrl'] . "/" . $stream['sStreamName'] . "." . $stream['sFlvUrlSuffix'] . "?";
$url = str_replace("amp;", "", $url);
$url = str_replace("backsrc", "huyalive", $url);
$url = str_replace("al.flv", "al.hls", $url);
$url = str_replace("aldirect.flv", "aldirect.hls", $url);
$url = str_replace("tx.flv", "tx.hls", $url);
$url = str_replace(".flv?", ".m3u8", $url);
}
}
//这个循环出来 如果有多个直播源的话 $url应该是最后一个直播源
$raw_data = $hyPlayerConfig['stream']['data'][0]['gameLiveInfo'];
//打包解析结果 把抓取到的直播间信息尽量包装成斗鱼接口那样 保持接口的一致性
$parse_result = ["type" => "strjson", "Rendata" => ["media_type" => "live", "data" => [
"roomName" => $raw_data['roomName'],
"nickname" => $raw_data['nick'],
"avatar" => $raw_data['avatar180'],
"roomimg" => $raw_data['screenshot'],
"roominfo" => $raw_data['introduction']
], "link" => $url, "time" => time()], "info" => "Check-OK", "state" => "SUCCESS"];
//存入数据库 略
} else {
return null;
}
return $parse_result;
}
十分感谢
「real-url」和「live-real-url」两个开源项目提供的更为便捷的思路
两个项目关于获取虎牙直播源的逻辑非常近似,可以视为同一种思路。
我们先看 Python 版:
def get_real_url(rid):
room_url = 'https://m.huya.com/' + str(rid)
header = {
'Content-Type': 'application/x-www-form-urlencoded',
'User-Agent': 'Mozilla/5.0 (Linux; Android 5.0; SM-G900P Build/LRX21T) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Mobile Safari/537.36'
}
response = requests.get(url=room_url, headers=header)
pattern = r"hasvedio: '([\s\S]*.m3u8)"
result = re.findall(pattern, response.text, re.I)
if result:
real_url = result[0]
real_url = re.sub(r'_1200[\s\S]*.m3u8', '.m3u8', result[0])
else:
real_url = '未开播或直播间不存在'
return real_url
再看 JAVA 版:
private static final Pattern PATTERN = Pattern.compile("(?<=hasvedio: ')(.*\\.m3u8)");
private static String get_real_url(String rid) {
String room_url = "https://m.huya.com/" + rid;
String response = HttpRequest.create(room_url)
.setContentType(HttpContentType.FORM)
.putHeader("User-Agent", "Mozilla/5.0 (Linux; Android 5.0; SM-G900P Build/LRX21T) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Mobile Safari/537.36")
.get().getBody();
Matcher matcher = PATTERN.matcher(response);
if (!matcher.find()) {
return null;
}
String result = matcher.group();
if (StringUtils.isBlank(result)) {
return "未开播或直播间不存在";
}
return result.replaceAll("_\\d{3,4}\\.m3u8", ".flv");
}
同样都是利用User-Agent伪装手机去访问手机版虎牙,然后正则匹配hasvedio这个字段的值,不用费老半天劲再组装,匹配出来直接就是直播源。
而且我猜测手机版页面应该是比电脑版要小的,那就相当于提高了处理效率,减少了响应时间。
提升的这部分也许没办法直观感受到,但打个比方,现在是爬一个直播源,假如我们要爬某个分区前一百个直播源呢,两百个呢,所有分区呢?
当然前一种思路我亲手测试也是可行的,解题思路永远不嫌少,这个方法在这里不是最优解,换个问题未必也不是。
Bilibili
B 站的直播源就很神奇了,抓取难度处于困难和简单的叠加态。为什么这么说?
假如现在你就是爬虫(人形爬虫,听起来很~好 ch~ 可怕的样子),虽然你没有任何编程基础,你要做的是:
(不必照着做,如果只是想要 B 站直播源,后面有更简单的方式,这里是介绍一种比较通用的、手动获取直播源的方式)
- 打开你要抓取直播源的直播间
- F12 打开「开发者工具」
- 切到「Network」标签
- 看到左上角的红点了吗,不是它,它的右边有个「Clear」按钮,点一下清空之前记录的数据
- F5 刷新
- 等待 10s 左右,直到时间轴图像里有「长长的一条蓝线贯通左右」
- 拖动鼠标选中一段「只有这条蓝线」的区域
- 下面出现数个 XHR,不用在意 XHR 是什么,滚轮滚到最上面,有一个
live_开头的 - 点击它,弹出详情,你第一眼看到的,也就是「Header」标签的「General」项的「Request URL」,内容类似
https://cn-jswx2-cmcc-live-02.bilivideo.com/live-bvc/xxxxxx/live_xxxx_xxxxxxx_xxxx.flv?后面是一堆参数略 - 只取
live_xxxx_xxxxxxx_xxxx这一段,在前面加https://cn-hbxy-cmcc-live-01.live-play.acgvideo.com/live-bvc/,后面加.m3u8,完成
很简单吧。
现在换成服务器自动化流程。
我做不到。
故技重施,curl 直播间页面,B 站只会给「出错了」的提示页面。
使用 B 站的官方接口,获取开播状态没什么问题,但是,两个接口获取到的durl(直播源)都是null。
header 改了个遍,User-Agent改成手机,改成正经浏览器,因为本地的 postman 都能拿到数据我甚至假装过 postman。
当然 IP 和来源都伪装过了,但就是拿不到,这玩意 debug 都很难找到方向。
不太清楚 B 站的反爬在业界内算不算强的,不过打我这个菜鸡是绰绰有余了。
所以目前我自己的 API 没有实现 b 站的直播源。
查了很多资料得知大概率是 IP 问题,因为一些国外 IP 也是同样的情况(拿不到 durl 这个字段)。
所以也许不是反爬有多厉害,是 IP 黑名单强?
我的腾讯云装的 windows,于是我把脚本拿去服务器上简单试了一下。
同一时间同一直播间,本地没有任何问题,服务器上的会卡在某个阶段,具体哪个步骤懒得 debug 了。
我的网站放在阿里云,刚刚说过了也取不到关键值。
初步猜测重要数据接口把来自主流机房的 IP 的拉黑了,这部分有空我会持续跟进。
虽然我买不起群晖,但我可以把吃灰的树莓派翻出来啊。
实在没办法了,老老实实上代 {过}{滤} 理 IP 池也不是不行。
只要你有一颗爱折腾的心,办法总比困难多。
说话回来,这样大家对「大型爬虫为什么都要上分布式」也有一个形象的认识了,一是提高负载能力,二是反反爬。
当然我们本地 PC,家用的宽带,本地的软件,这样的情况直接从 B 站官方接口拿数据是没问题的。
访问https://api.live.bilibili.com/room/v1/Room/room_init?id=直播间房间号,返回的 json->data->live_status 就是当前直播状态,1 开播 0 没有,我们叫它接口 1。
访问https://api.live.bilibili.com/room/v1/Room/playUrl?cid=直播间房间号&platform=h5&otype=json&quality=4,返回的 json->data->durl 就是各个画质的直播源,我们叫它接口 2。
访问https://api.live.bilibili.com/xlive/web-room/v1/index/getRoomPlayInfo?room_id=直播间房间号&play_url=1&mask=1&qn=0&platform=web,可以看到返回的 json->data 里既有live_status这个字段,还有个play_url字段,durl也在这个play_url里面,我们叫它接口 3。
对比三个接口的数据,我们很容易就能得出「接口 3」就是「接口 1」+「接口 2」的结论。
(其实从room_init、playUrl、getRoomPlayInfo三个域名上就能初步猜测,不过大胆假设完还要小心求证嘛)
然后就看你的需求了,如果你只是想做一个开播提醒工具,tg 机器人也好,qq 机器人也好,微信公众号也好,邮件也好甚至短信也好,使用接口 1 就行了(反正接口 2、3 也没有更多的直播间标题等信息,还是要继续找其他接口)。
如果你想做一个开播查询工具,开播了就放没播就提示的话,用接口 3 避免了两次请求两个接口的繁琐步骤。
如果你只是单纯的想要直播源,打开浏览器访问接口 2(https://api.live.bilibili.com/room/v1/Room/playUrl?cid=直播间房间号&platform=h5&otype=json&quality=4),Ctrl + F 搜索live_,有四个结果(不用选,四个都是一样的),取live_到.m3u8这一段,在前面加上https://cn-hbxy-cmcc-live-01.live-play.acgvideo.com/live-bvc/,B 站直播源 get。
而且从「即使直播间没开播,接口 2 依然能够获取 durl(接口 3 不行 durl 值为 null)」这个现象来看,B 站的直播源很可能是接近永久(没事不会变化)的长期直播源。
B 站直播整活不太行,24 小时直播的影视频道还是挺有价值的,当成没广告的电影台看没什么问题。而且类型相对集中,比方说你喜欢恐怖片,有些直播间就只放恐怖片。
电视剧、相声、电台同理,虽然不知道现在还有没有。
成品
好了,三个直播站的直播源获取方式都介绍完了,那么有没有一个可以检测三个站开播状态,如果开播则返回直播源,并且既可以选择直接用指定的本地播放器播放,也可以选择将直播源生成 asx 文件的小工具呢?
巧了,我这里还真有一个,免费(废话都开源了),安全可靠,兼容性强。
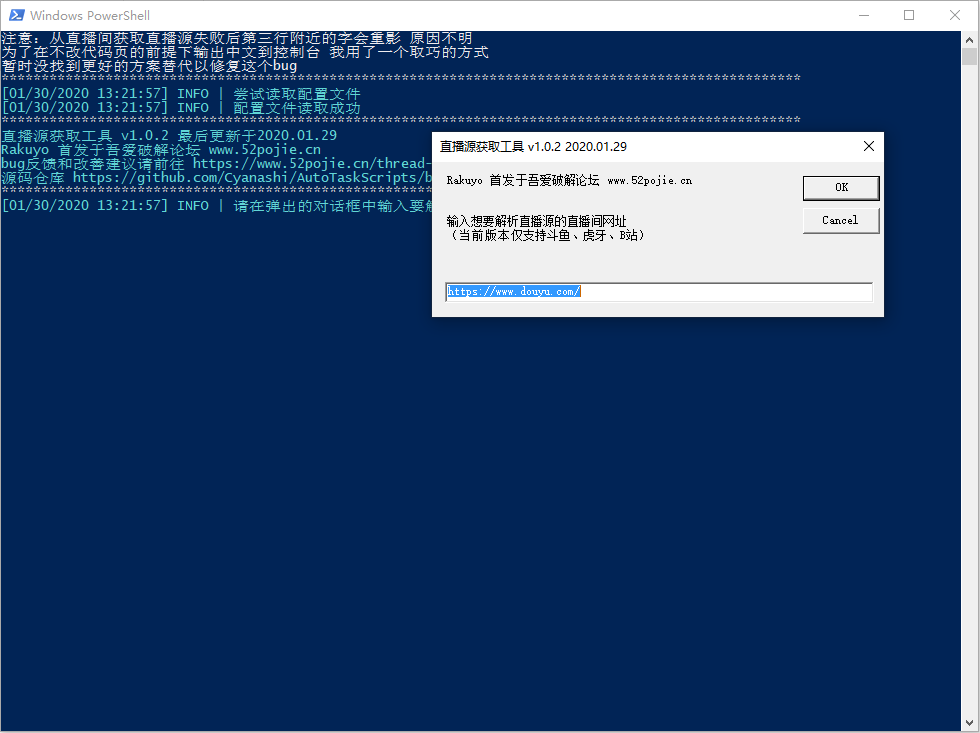
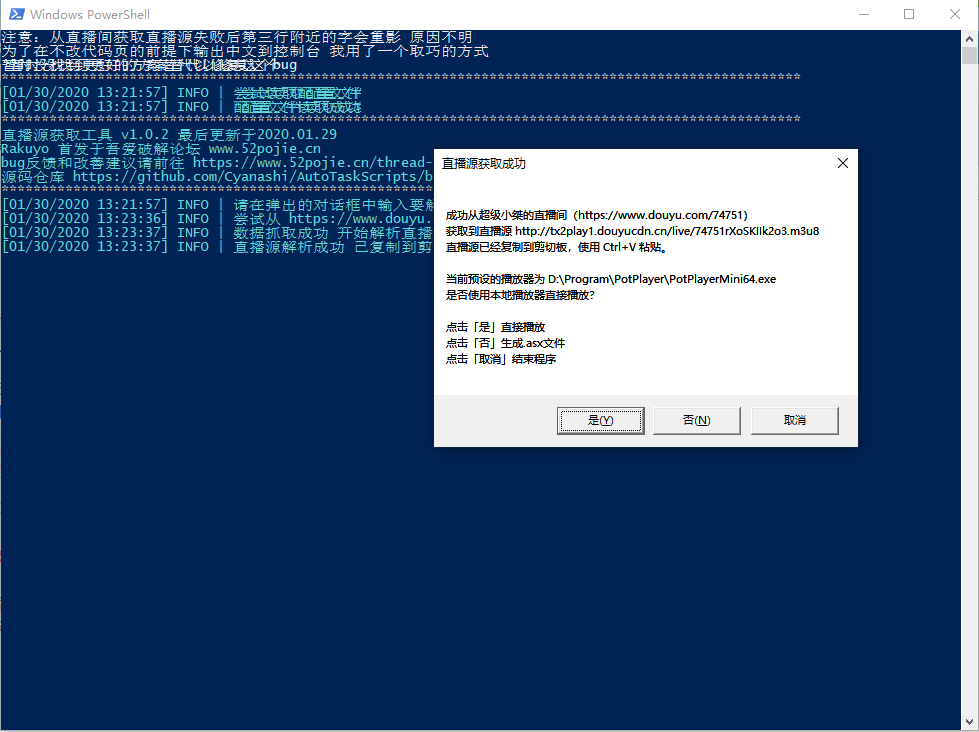
用 powershell 写的,只要你是 win10,不需要安装任何依赖,点开就能跑。
本质是脚本文件,用编辑器打开就能看到所有源码,不放心的话用电子显微镜一行一行检查都行。
本来是纯命令行,想想都用 powershell 写了,不说上 wpf,整两个对话框不过分吧。
写着写着发现本来就没几个的功能完全可以都搬到对话框里完成,用起来居然还意外的顺手(至少比命令行舒服多了)。
食用方法
具体的基本用法打开工具一看就懂,此处不再赘述。
(小工具虽然很简陋,也有勉强还算友好的用户界面。)
这里介绍一下进阶用法。
命令行
Start-Process powershell -ArgumentList "D:\Workspace\Powershell\project\live\GetStreamLink.ps1 [播放器路径] [直播间地址]"
# 两个参数可以呼唤位置
./GetStreamLink.ps1 [播放器路径] [直播间地址]
# 和
./GetStreamLink.ps1 [直播间地址] [播放器路径]
# 都是一样的
默认直播间
如果你觉得用命令行还是太麻烦的话可以配置默认直播间。
初次运行脚本后会生成配置文件config.xml,里面的<default></default>标签里有对<url></url>,在里面填上直播间地址之后,如果不带参数地打开程序,就会自动指定配置文件里的网址,而不必再手动输入。
缺点是目前只能指定一个,暂时没有做顺序列表的预定
site 和 room_id 是为了以后扩展更方便的输入方式(比如只需要输直播间房间号)用的,现在没用
asx 文件的玩法
asx 其实就是一个功能特化的 xml 配置文件,它的默认打开方式是播放器,打开就会播放预先设定好的流媒体,乍一看非常神奇。
随便用什么文本编辑器打开这个文件,可以看到类似 xml 的结构,构成非常简单。
每个<entry />标签里面都是一个独立的流媒体源,<title />是名字,<ref />里面是 url,一看就明白。
所以你可以手动把<title />改成你喜欢的名字,这样在播放器里哪个是哪个会更加一目了然。
另外同一个 asx 文件是可以包含若干个<entry />标签的,也就是说你可以手动编辑文件:
<asx version="3.0">
<entry>
<title>直播间1</title>
<ref href="#直播间1的url"/>
</entry>
<entry>
<title>直播间2</title>
<ref href="#直播间2的url"/>
</entry>
<entry>
<title>电台3</title>
<ref href="#电台3的url"/>
</entry>
</asx>
接下来只需要打开一个文件,所有流媒体源都被添加进来了,之后可以在播放器里选择播放哪个。
最后,asx 文件和一切脚本文件一样,写好内容之后保存退出,把新建文本文档.txt重命名成现在你是直播源了.asx也能用。
下载方式
「蓝奏 密码 52pojie」「度盘 提取码 52pj」
「Github Repo Fragment」复制粘贴到本地新建文本文档,修改后缀名为. ps1 即可
欢迎反映 BUG 或提出改进意见~
顺便提下用法,解压之后是. ps1 文件(powershell 脚本),win10 当成 exe 直接执行就行
控制台和提示框都是中文,输出信息也尽量详尽,我实在不知道还要怎么说明了……
顺手编译了个 exe 版,因为编译后控制台输出中文乱码,暂时没找到解决方案,所以控制台没有输出
而且不会创建配置文件,所以会缺失部分进阶功能(好像对用不到进阶的用户来说反而更好了?)
仍然推荐 ps1 版,毕竟如果没有逆向基础,我在 exe 里塞了什么东西你也不知道
随便用个文本编辑器打开就看得到源码的东西用起来也更放心不是?
Tips:
Q:我不需要原画,我就是喜欢 2000/4000(码率?)画质,行不行?
A:行,_2000p这一段可以保留,也可以自行替换成_4000p(大概代表蓝光 4M?)。
Q:一定要改成.m3u8格式才可以吗?
A:不是,它不是格不格式的问题,~它真的是那种~ 它本质就是一个 url,你把它看成一个网址,这个网址一直在推送视频流数据出来。现在我们拿个桶来接水,你用不一样的水龙头,它出来的水会不一样吗。你想改成.xs也好,就.flv不动也罢,水源已经找到了,想怎么接水你高兴就好。
Q:好乱啊,这么多启动方式如果同时使用,到底谁先谁后?
A:优先级从上至下:使用命令行参数启动,配置文件设置了 default->url,启动时剪切板有合法的直播间地址,配置文件同时设置了 default->site/room_id,前面说的都没有直接启动才会弹出输入框要求输入。
更新日志
2020.1.31 更新 v1.0.3
- [新增] 如果剪切板已有直播间地址,则打开工具后不再询问直接使用该地址进行解析
- [修复] 某些斗鱼直播间去掉清晰度后缀后会无法播放,因此获取到的斗鱼直播源统一加上
_4000p的清晰度后缀 - [优化] 优化了提取直播间房间号的正则表达式
- [优化] 优化了部分判断逻辑 重命名部分函数使得含义更易理解
- [优化] 获取到的网页对象不再解析 DOM 树以提高运行效率(感谢 strmoon 的建议)
2020.2.10 更新 v1.0.4
- [新增] 如果配置文件设定了直播站,可以直接输入房间号进行解析;如果配置文件同时设定了直播站和房间号,则直接进行解析
- [新增] 支持了网易 cc 的临时直播源,感谢「天川天音的提议」和「网易 CC 直播源抓取分析过程」一文提供的思路
- [修复] 以各种方式启动后的直播间地址部分处理逻辑错误
2020.3.5 更新 v1.0.5
-
[修复] 虎牙直播源失效
TODO
-
[ ] 修复已知 BUG:如果直播间处于下播后的轮播状态,可能会误判正在直播而尝试无效抓取(点名批评斗鱼暴雪直播间)
-
[ ] 新增 tan01 建议的功能:支持自定义和保存直播间信息和直播源(个人暂时没这个需求懒得写 hhh,闲下来再说)

Comments | NOTHING